
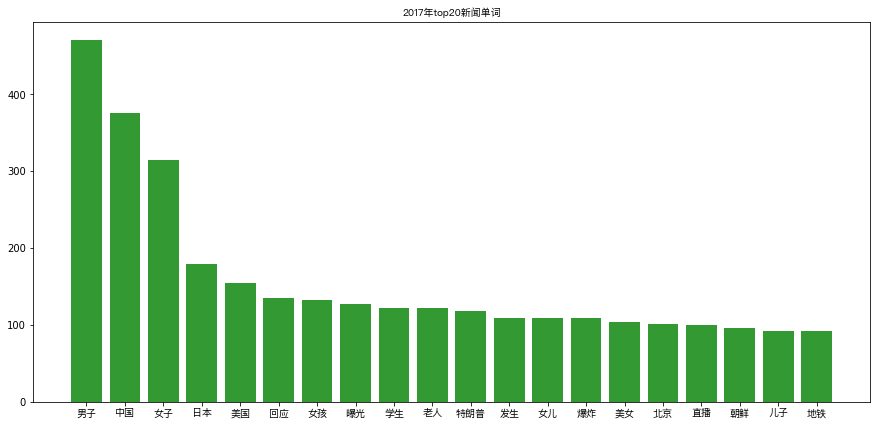
新闻热词:2017年的top20高频词
数据集
数据读取
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
dataPath="../data/hotquery.news.csv"
COLUMNS = ["query", "source", "category", "date"]
dataset = pd.read_csv(tf.gfile.Open(dataPath),sep="\t",encoding='utf8',header=None,names=COLUMNS)
数据分析
dataset.head(5)
| query | source | category | date | |
|---|---|---|---|---|
| 0 | 找小姐拒付嫖资 | baidu | society | 2017-02-25 14:45:42.0 |
| 1 | 印度女星遭轮奸 | baidu | ent | 2017-02-25 14:45:42.0 |
| 2 | 高校招生30禁令 | baidu | society | 2017-02-25 14:45:42.0 |
| 3 | 王菲谢霆锋热吻 | baidu | ent | 2017-02-25 14:45:43.0 |
| 4 | 南非爆发排外游行 | baidu | society | 2017-02-25 14:45:43.0 |
dataset.shape
(16817, 4)
dataset.groupby('source').size()
source
360 567
baidu 8517
shenma 1838
sogou 3379
unknown 2243
weixin 273
dtype: int64
dataset.groupby('category').size()
category
auto 37
china 279
ent 1907
finance 121
mil 61
society 5887
sports 101
tech 65
unknown 8181
world 178
dtype: int64
对热词进行分词
import jieba
class Segment:
def cut(self, words):
seg_list = jieba.cut(words, cut_all=False)
return seg_list
import re
segment = Segment()
def clean(string):
chinese_only = string.lower()
list = segment.cut(chinese_only)
meaningful_words = [w for w in list if w.strip()]
return meaningful_words
print ",".join(clean(u"jieba分词"))
jieba,分词
dataset["keywords"] = dataset["query"].map(clean)
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/jw/_2n4n7v92sxg2sckwl6k8kt00000gp/T/jieba.cache
Loading model cost 0.408 seconds.
Prefix dict has been built succesfully.
统计top20单词
# 统计词频
word_freq = {}
for words in dataset["keywords"]:
for word in words:
if len(word) <= 1:
continue
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 1
# 排序
sort_word = []
for word,freq in word_freq.items():
sort_word.append((word,freq))
sorted_word = sorted(sort_word,key = lambda x:x[1], reverse = True)
# 选取top word
x = []
y = []
for word in sorted_word[:20]:
x.append(word[0])
y.append(word[1])
图表展示
fontset = FontProperties(fname='/System/Library/Fonts/PingFang.ttc') # 环境:macos, 解决pyplot中文乱码问题
x_pos = np.arange(len(x))
plt.figure(figsize=(15,7))
plt.xticks(x_pos,x, fontproperties=fontset)
plt.bar(x_pos,y,align='center',color='green',alpha=0.8)
plt.title(u"2017年top20新闻单词", fontproperties=fontset)
plt.show()
留下评论